![]()
36 - Distributing Calls on Glue Interactive sessions¶
AWS SDK for pandas is pre-loaded into AWS Glue interactive sessions with Ray kernel, making it by far the easiest way to experiment with the library at scale.
In AWS Glue Studio, choose Notebook to create an AWS Glue interactive session:
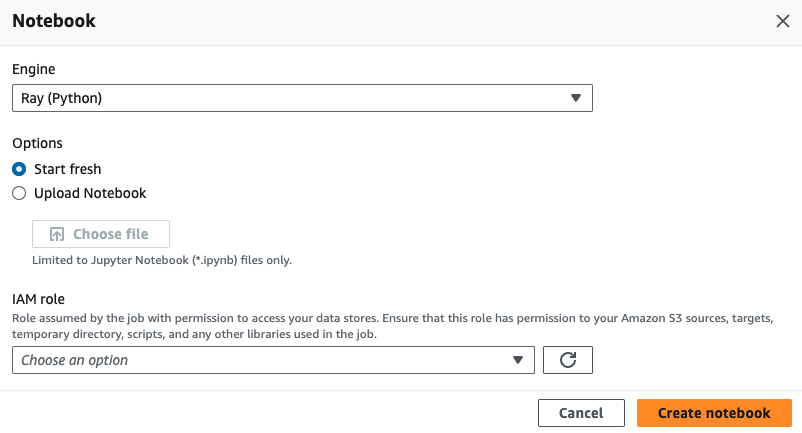
Then select Ray as the kernel. The IAM role must trust the AWS Glue service principal.
Once the notebook is up and running you can import the library. You can install awswrangler and modin as additional dependencies.
[16]:
%additional_python_modules awswrangler,modin
Additional python modules to be included:
awswrangler
modin
[1]:
import awswrangler as wr
Authenticating with environment variables and user-defined glue_role_arn: arn:aws:iam::463623607974:role/service-role/AmazonSageMakerServiceCatalogProductsGlueRole
Trying to create a Glue session for the kernel.
Worker Type: Z.2X
Number of Workers: 5
Session ID: 32566e82-34d2-4db7-adac-cbee573e20bf
Job Type: glueray
Applying the following default arguments:
--glue_kernel_version 0.38.1
--enable-glue-datacatalog true
--auto-scaling-ray-min-workers 1
--additional-python-modules awswrangler,modin
Waiting for session 32566e82-34d2-4db7-adac-cbee573e20bf to get into ready status...
Session 32566e82-34d2-4db7-adac-cbee573e20bf has been created.
[8]:
df = wr.s3.read_parquet(path="s3://ursa-labs-taxi-data/2017/")
[9]:
df.head()
vendor_id pickup_at ... improvement_surcharge total_amount
0 1 2017-01-09 11:13:28 ... 0.3 15.300000
1 1 2017-01-09 11:32:27 ... 0.3 7.250000
2 1 2017-01-09 11:38:20 ... 0.3 7.300000
3 1 2017-01-09 11:52:13 ... 0.3 8.500000
4 2 2017-01-01 00:00:00 ... 0.3 52.799999
[5 rows x 17 columns]
To avoid incurring a charge, make sure to delete the Jupyter Notebook when you are done experimenting.