![]()
14 - Schema Evolution¶
awswrangler supports new columns on Parquet and CSV datasets through:
wr.s3.store_parquet_metadata() i.e. “Crawler”
[1]:
from datetime import date
import pandas as pd
import awswrangler as wr
Enter your bucket name:¶
[2]:
import getpass
bucket = getpass.getpass()
path = f"s3://{bucket}/dataset/"
···········································
Creating the Dataset¶
Parquet Create¶
[3]:
df = pd.DataFrame(
{
"id": [1, 2],
"value": ["foo", "boo"],
}
)
wr.s3.to_parquet(df=df, path=path, dataset=True, mode="overwrite", database="aws_sdk_pandas", table="my_table")
wr.s3.read_parquet(path, dataset=True)
[3]:
| id | value | |
|---|---|---|
| 0 | 1 | foo |
| 1 | 2 | boo |
CSV Create¶
[ ]:
df = pd.DataFrame(
{
"id": [1, 2],
"value": ["foo", "boo"],
}
)
wr.s3.to_csv(df=df, path=path, dataset=True, mode="overwrite", database="aws_sdk_pandas", table="my_table")
wr.s3.read_csv(path, dataset=True)
Schema Version 0 on Glue Catalog (AWS Console)¶
Appending with NEW COLUMNS¶
Parquet Append¶
[4]:
df = pd.DataFrame(
{"id": [3, 4], "value": ["bar", None], "date": [date(2020, 1, 3), date(2020, 1, 4)], "flag": [True, False]}
)
wr.s3.to_parquet(
df=df,
path=path,
dataset=True,
mode="append",
database="aws_sdk_pandas",
table="my_table",
catalog_versioning=True, # Optional
)
wr.s3.read_parquet(path, dataset=True, validate_schema=False)
[4]:
| id | value | date | flag | |
|---|---|---|---|---|
| 0 | 3 | bar | 2020-01-03 | True |
| 1 | 4 | None | 2020-01-04 | False |
| 2 | 1 | foo | NaN | NaN |
| 3 | 2 | boo | NaN | NaN |
CSV Append¶
Note: for CSV datasets due to column ordering, by default, schema evolution is disabled. Enable it by passing schema_evolution=True flag
[ ]:
df = pd.DataFrame(
{"id": [3, 4], "value": ["bar", None], "date": [date(2020, 1, 3), date(2020, 1, 4)], "flag": [True, False]}
)
wr.s3.to_csv(
df=df,
path=path,
dataset=True,
mode="append",
database="aws_sdk_pandas",
table="my_table",
schema_evolution=True,
catalog_versioning=True, # Optional
)
wr.s3.read_csv(path, dataset=True, validate_schema=False)
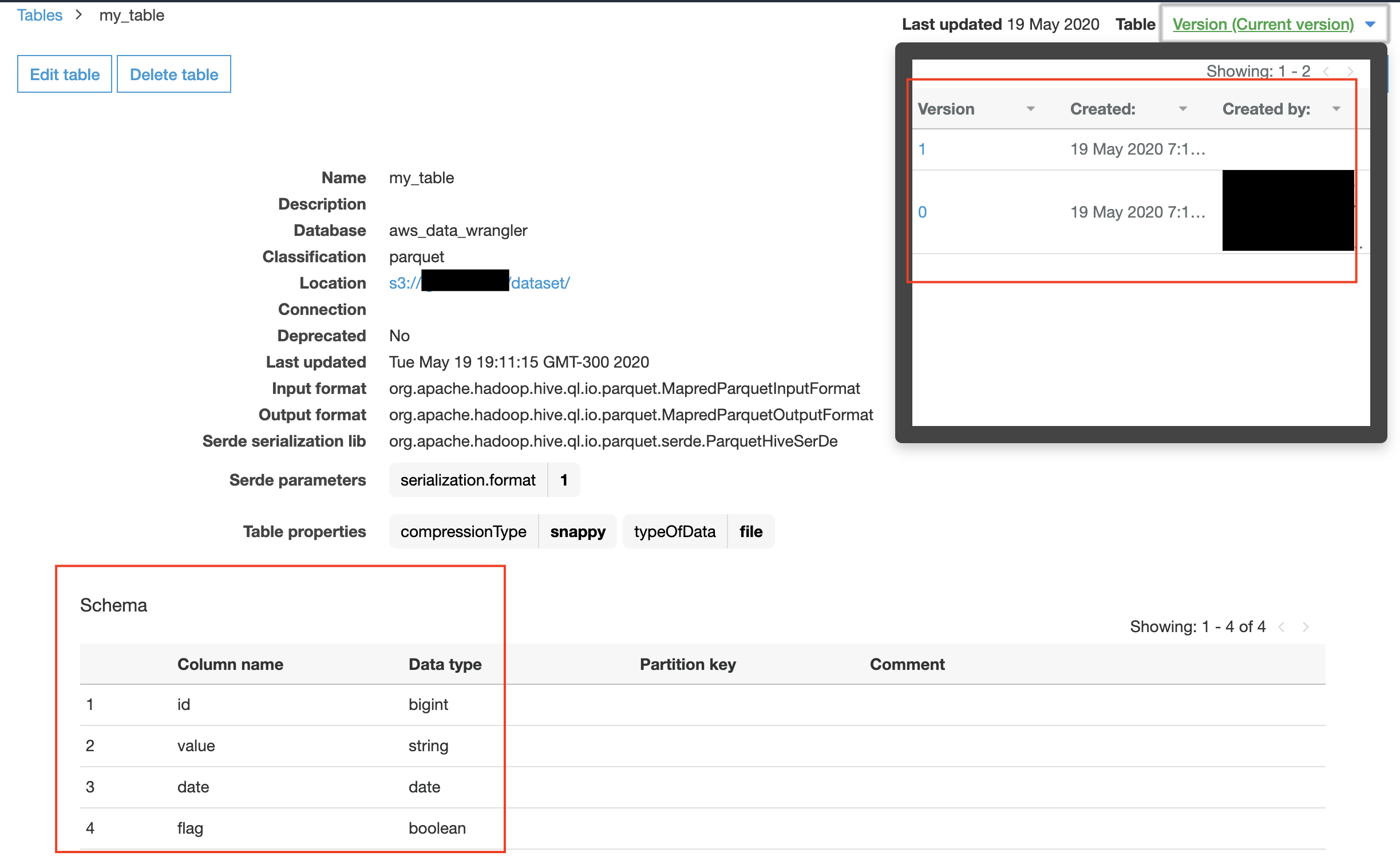
Schema Version 1 on Glue Catalog (AWS Console)¶
Reading from Athena¶
[5]:
wr.athena.read_sql_table(table="my_table", database="aws_sdk_pandas")
[5]:
| id | value | date | flag | |
|---|---|---|---|---|
| 0 | 3 | bar | 2020-01-03 | True |
| 1 | 4 | None | 2020-01-04 | False |
| 2 | 1 | foo | None | <NA> |
| 3 | 2 | boo | None | <NA> |
Cleaning Up¶
[6]:
wr.s3.delete_objects(path)
wr.catalog.delete_table_if_exists(table="my_table", database="aws_sdk_pandas")
[6]:
True